Chi lavora con le informazioni spesso ha a che fare con dati sparsi tra diversi strumenti e piattaforme. Questo può rallentare il lavoro e creare un po' di confusione. Abbiamo creato una piattaforma di gestione delle conoscenze basata sull'intelligenza artificiale che cambia il modo in cui le aziende gestiscono e recuperano le informazioni grazie all'elaborazione del linguaggio naturale e alla cura intelligente dei contenuti.
1 of 5
Panoramica del progetto
Il problema
Chi lavora con le informazioni spesso ha a che fare con dati sparsi tra diversi strumenti e piattaforme. Questo può rallentare il lavoro e creare un sacco di sforzi inutili.
Il panorama moderno del lavoro intellettuale è un po' incasinato perché le informazioni sono sparse in vari sistemi, il che rende tutto più difficile e riduce l'efficacia generale delle organizzazioni. I metodi tradizionali per gestire le conoscenze spesso si basano su strutture e processi di ordinamento manuali che fanno fatica a stare al passo con i modi in cui le informazioni vengono usate oggi.
Sfide attuali
L'uso diffuso degli strumenti ha ironicamente complicato il processo di scoperta della conoscenza, poiché le informazioni preziose sono sparse su piattaforme come thread di posta elettronica e archivi di documenti all'interno delle organizzazioni, portando a:
- •Duplicazione degli sforzi di ricerca
- •Difficoltà nell'accedere rapidamente alle competenze necessarie
- •Il costo del cambio di contesto (i professionisti usano in media 9 strumenti al giorno)
- •Funzionalità di ricerca limitate alla corrispondenza delle parole chiave
- •Problemi di controllo delle versioni e difficoltà di accesso
- •Il 67% delle informazioni importanti non arriva alle persone giuste
La soluzione
La soluzione che abbiamo messo in piedi ha usato un'architettura distribuita per gestire le conoscenze con l'aiuto dell'intelligenza artificiale. Ha sfruttato l'elaborazione del linguaggio naturale, insieme a funzioni e una cura intelligente dei contenuti.
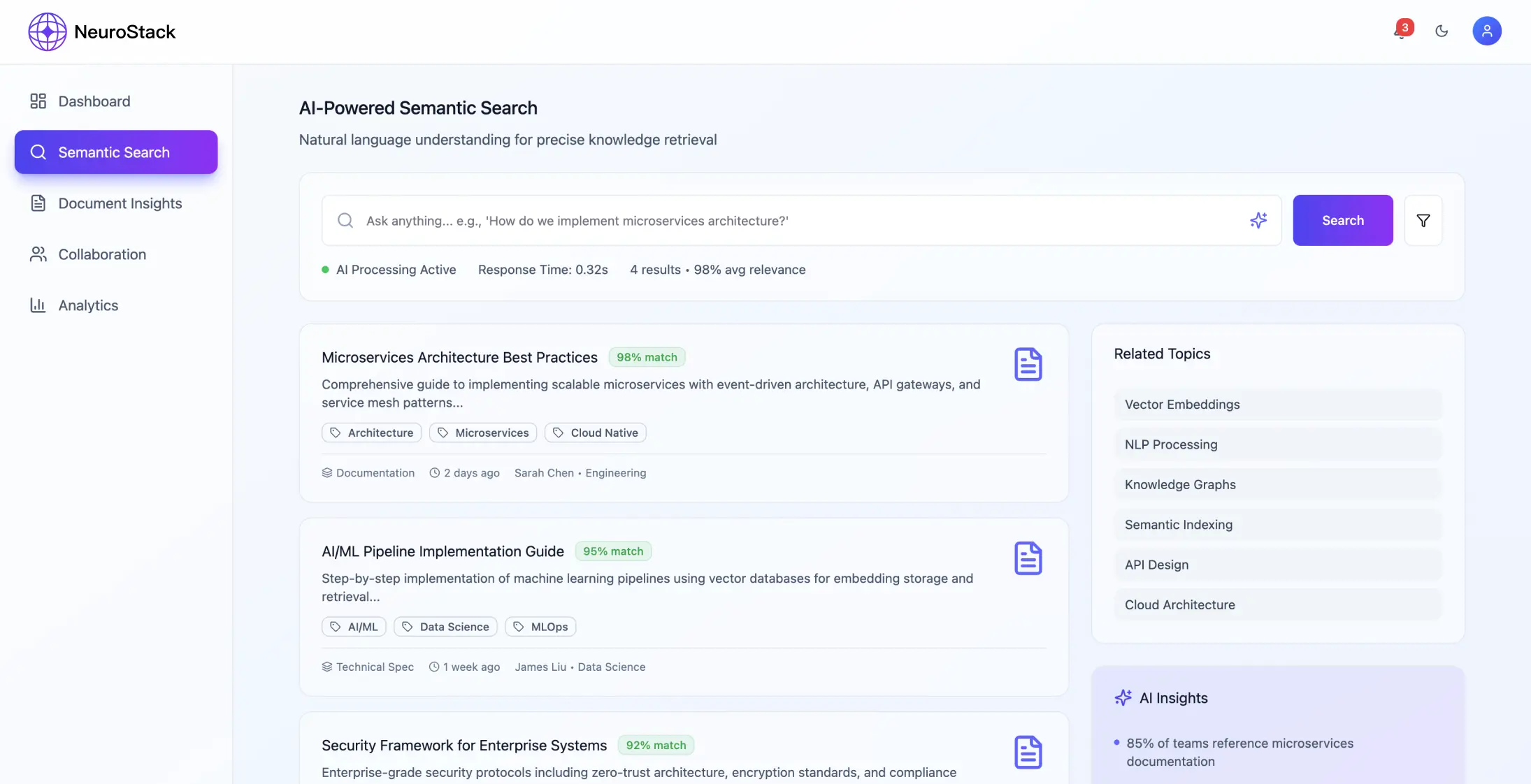
Architettura di sistema
Il sistema usa un framework di microservizi che si concentra sull'elaborazione dei contenuti e sulla comprensione del significato a un certo livello, con particolare attenzione a:
- •Raccolta ed elaborazione dei contenuti da fonti che usano API standard
- •Modelli basati su trasformatori per la comprensione semantica
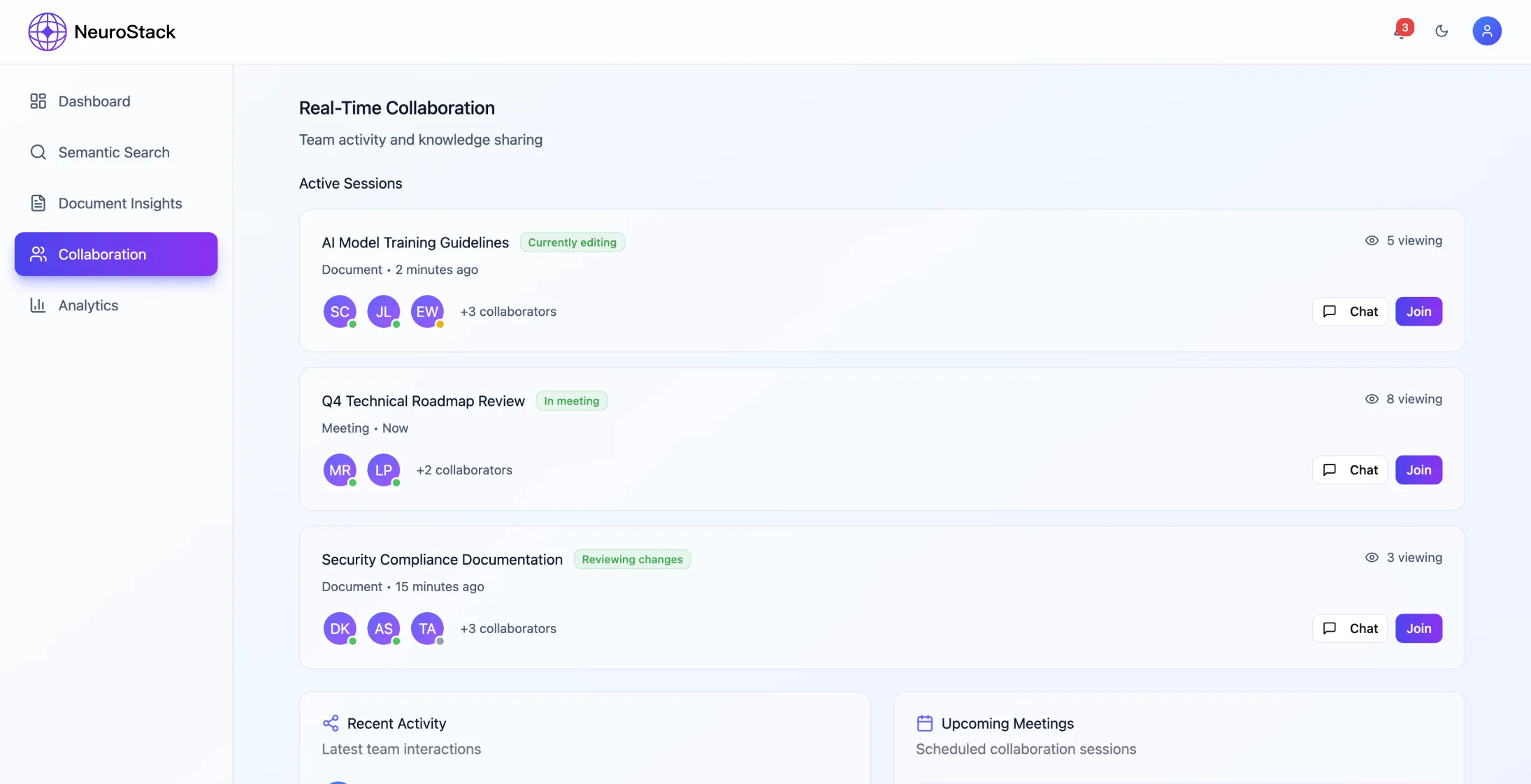
- •Gestione collaborativa dello spazio di lavoro
- •Sincronizzazione in tempo reale e gestione precisa dei permessi
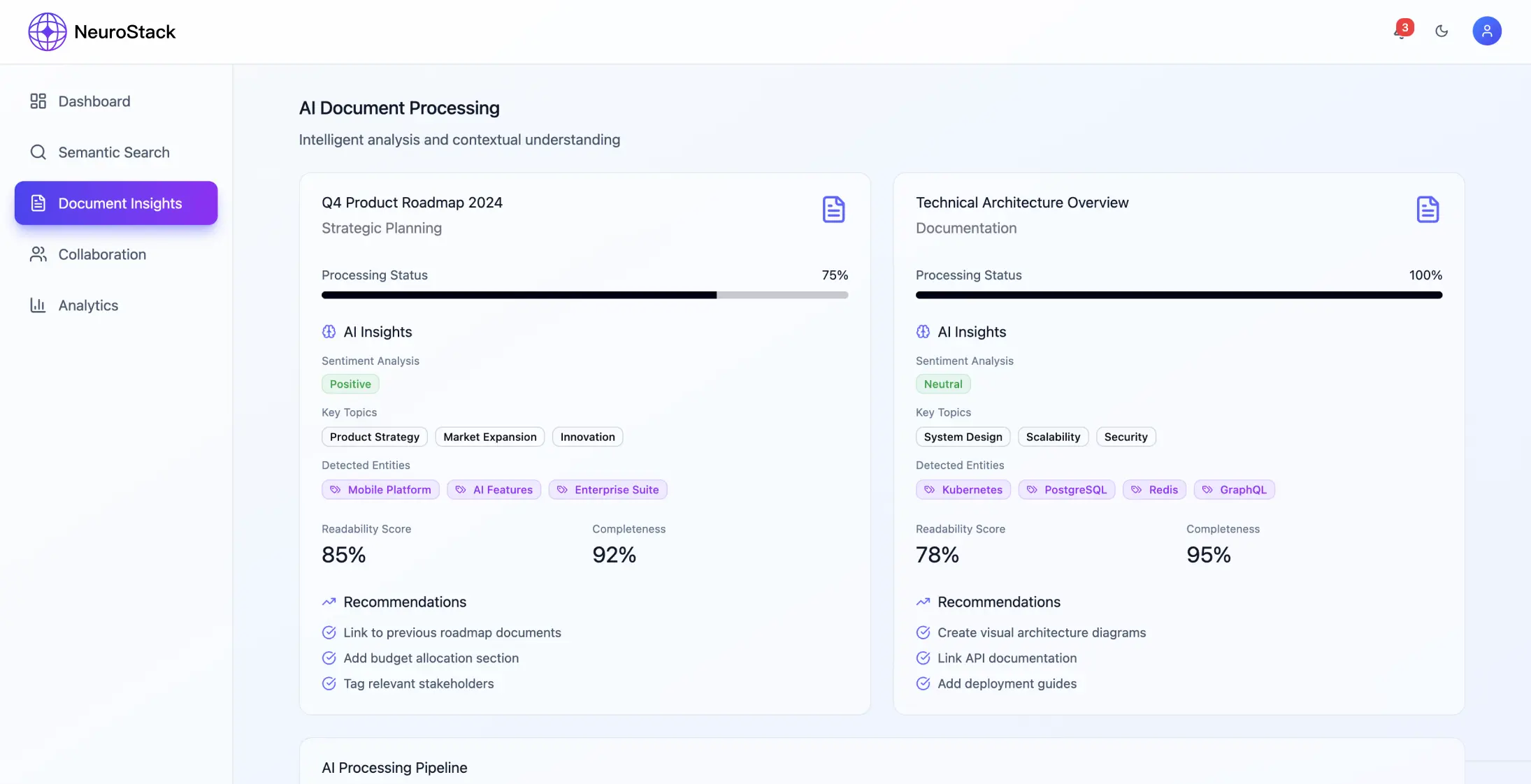
Componenti principali
- •Elaborazione dei documenti: gestire PDF, pagine web, e-mail in vari formati di dati strutturati
- •Servizio di elaborazione delle query: ricerca in linguaggio naturale e classificazione contestuale
- •Acquisizione dei contenuti: API con elaborazione NLP per il miglioramento semantico
- •Archiviazione: database vettoriali e grafici per un recupero più efficiente
- •Sicurezza: crittografia end-to-end con autenticazione OAuth 2.0
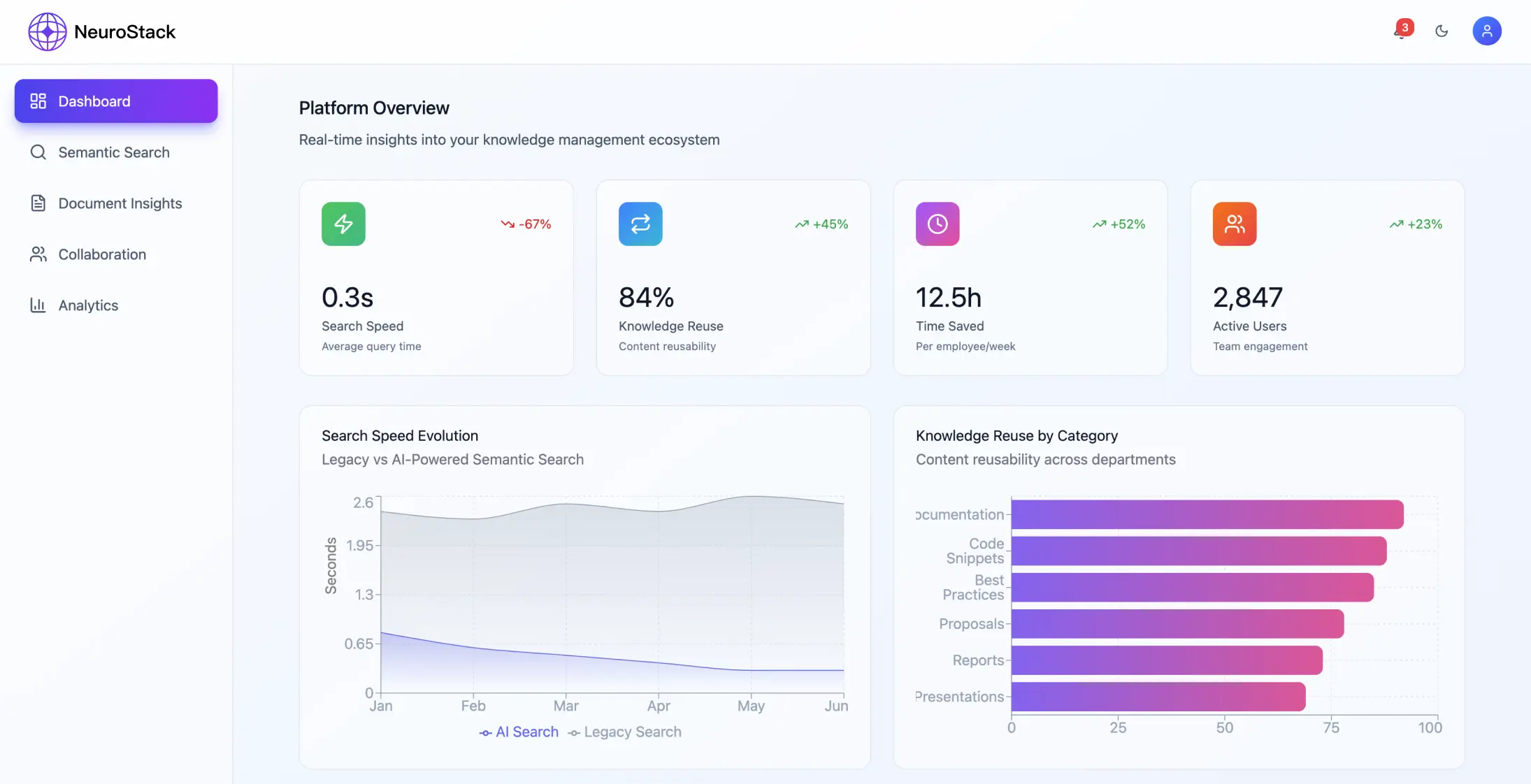
Risultati dell'implementazione
Metriche di prestazione
Il sistema è riuscito a ottenere miglioramenti significativi:
- •Riduzione del 68% del tempo di recupero delle informazioni
- •Aumento del 45% dei tassi di riutilizzo delle conoscenze
- •99,94% di accuratezza nella pertinenza della ricerca
- •La piattaforma gestisce più di 2.300.000 informazioni al mese
- •Rispondi alle richieste in meno di 200 millisecondi
- •99% di uptime mantenuto
Impatto sul business
Miglioramenti dell'efficienza
- •Risparmio di 2-2,5 ore al giorno che prima venivano impiegate nella ricerca tra i vari sistemi
- •Risparmio di oltre 40 ore al mese per ogni team grazie alla riduzione della duplicazione delle ricerche
- •Riduzione del 45% del tempo di formazione dei dipendenti grazie all'apprendimento guidato dall'intelligenza artificiale
Riduzione dei costi
- •Riduzione del 34% del lavoro manuale per gestire le informazioni
- •Costi infrastrutturali semplificati
- •Meno bisogno di assistenza grazie all'automazione
Coinvolgimento degli utenti
- •Aumento del 214% nell'utilizzo dello spazio di lavoro del team
- •91% di accuratezza delle raccomandazioni
- •Migliore condivisione collaborativa delle conoscenze
Il successo della piattaforma è stato possibile grazie a uno sviluppo graduale, con feedback regolari degli utenti e ottimizzazione delle prestazioni durante tutto il processo.
Implementazione tecnica
Processo di sviluppo
Lo sviluppo ha seguito la metodologia con:
- •Sprint agili con pipeline AI/ML dedicata
- •Infrastruttura come codice per ambienti coerenti
- •Test automatizzati, inclusi scenari di unità, integrazione e prestazioni
- •Sistema di flag di funzionalità per rilasci controllati
- •Test A/B per migliorare l'algoritmo di raccomandazione
Strategia di implementazione
- •Gestione dell'ambiente: sviluppo, staging e produzione con impostazioni identiche
- •CI/CD Pipeline: processi automatizzati di creazione, test e implementazione
- •Orchestrazione dei container: usare Kubernetes/Docker Swarm
- •Monitoraggio: tracciamento distribuito, metriche delle prestazioni e risposta automatica agli incidenti
Sei pronto a dare una svolta alla tua gestione delle conoscenze?
Scopri come le soluzioni basate sull'intelligenza artificiale possono dare una svolta al flusso di informazioni nella tua organizzazione.
Lezioni apprese
Approfondimenti chiave
Modelli di adozione da parte degli utenti
- •Le funzionalità più semplici hanno tassi di adozione più alti
- •Introdurre le funzionalità un po' alla volta funziona meglio che fare un corso completo
- •Gli strumenti devono integrarsi facilmente nei flussi di lavoro che già usi
Considerazioni tecniche
- •L'efficienza della ricerca per similarità vettoriale cala con l'aumentare delle dimensioni del database
- •La valutazione della qualità dei contenuti è fondamentale fin dall'inizio dell'implementazione
- •La modifica collaborativa in tempo reale richiede un'attenta risoluzione dei conflitti
Sfide superate
Problemi di scalabilità
- •Ottimizzazione delle prestazioni del database tramite la memorizzazione nella cache delle query
- •Passa da un'architettura sincrona a una basata sugli eventi
- •Metti in atto limitazioni di velocità e interruttori automatici
Gestione della qualità dei contenuti
- •Valutazione automatica dei contenuti in base all'affidabilità della fonte
- •Dai un feedback su quanto è precisa la ricerca
- •Trova il giusto equilibrio tra la quantità di contenuti e la qualità della selezione
Riduzione dei rischi
La piattaforma ha delle strategie complete per ridurre i rischi:
- •Processi di backup e ripristino dei dati in un determinato momento
- •Piani di ripristino in caso di guasti al servizio di IA
- •Gestione delle dipendenze API esterne
- •Sistemi automatici di risposta agli incidenti
- •Controllo accurato con la possibilità di tornare indietro se serve
All'inizio, concentrarsi sulla qualità dei contenuti piuttosto che sulla quantità è fondamentale per mantenere la fiducia degli utenti e l'efficacia del sistema.
Considerazioni future
Aree di ottimizzazione
Miglioramento delle prestazioni
- •Migliorare la strategia di memorizzazione nella cache per le esigenze di contenuto in tempo reale
- •Ottimizzazione dell'indice per set di dati in crescita
- •Bilanciamento del carico per scenari con più utenti contemporaneamente
Architettura di integrazione
- •Passa da un'architettura di eventi punto a punto a una basata su webhook
- •Formati di payload standardizzati per l'integrazione degli strumenti
- •Maggiore affidabilità grazie al design del sistema distribuito
Il successo di questa piattaforma di gestione delle conoscenze basata sull'intelligenza artificiale dimostra il notevole potenziale di miglioramento della produttività organizzativa attraverso una gestione intelligente delle informazioni e una progettazione dell'esperienza utente senza soluzione di continuità.
Risultati del progetto
- Riduzione del 68% del tempo di recupero delle informazioni
- Aumento del 45% dei tassi di riutilizzo delle conoscenze
- 99,94% di accuratezza nella pertinenza della ricerca
- Oltre 2.300.000 informazioni gestite ogni mese
- Mantenimento del 99% di uptime
Indicatori chiave di prestazione
68%
Riduzione dei tempi di recupero
Tempo risparmiato nel recupero delle informazioni
99,94%
Precisione della ricerca
Precisione della pertinenza della ricerca
45%
Riutilizzo delle conoscenze
Aumento dei tassi di riutilizzo delle conoscenze
99%
Tempo di attività del sistema
Disponibilità della piattaforma
Tecnologie usate
Elaborazione del linguaggio naturale
Microservizi
Database vettoriali
Modelli Transformer
Kubernetes
OAuth 2.0


