Pracownicy umysłowi często mają do czynienia z informacjami rozproszonymi między różnymi narzędziami i platformami. Prowadzi to do spadku wydajności i powielania pracy. Opracowaliśmy opartą na sztucznej inteligencji platformę do zarządzania wiedzą, która rewolucjonizuje sposób, w jaki organizacje przetwarzają i wyszukują informacje dzięki przetwarzaniu języka naturalnego i inteligentnej kuracji treści.
1 of 5
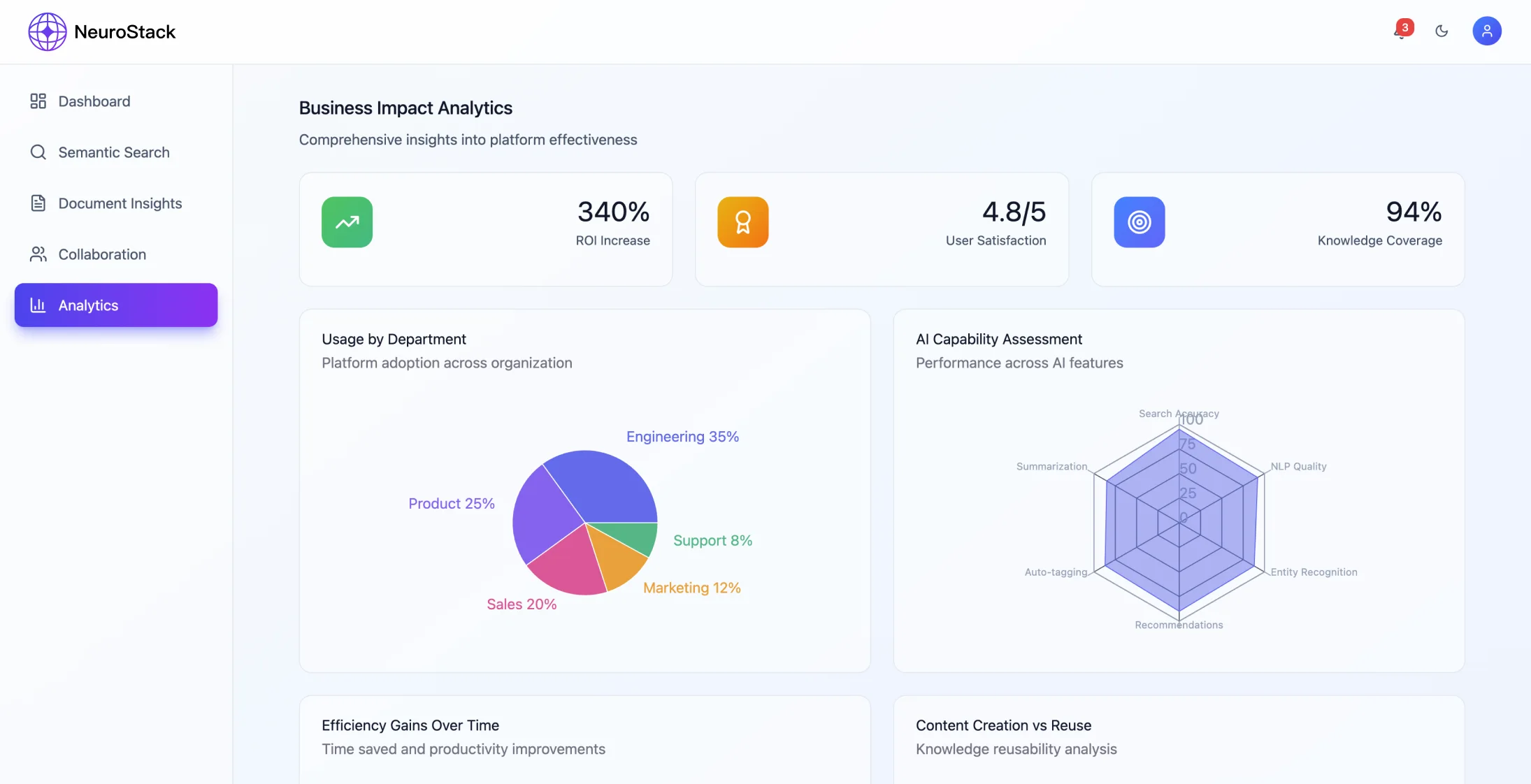
Przegląd projektu
Problem
Pracownicy wiedzy często mają do czynienia z informacjami rozproszonymi między różnymi narzędziami i platformami. Prowadzi to do spadku wydajności i powielania pracy. Współczesna rzeczywistość pracy opartej na wiedzy jest nękana przez rozproszony charakter informacji w różnych systemach, co powoduje dodatkowe obciążenie i zmniejsza ogólną efektywność organizacji. Konwencjonalne metody zarządzania wiedzą często opierają się na strukturach i ręcznych procesach sortowania, które z trudem nadążają za ewoluującymi sposobami wykorzystywania informacji w dzisiejszych czasach.
Aktualne wyzwania Powszechne stosowanie narzędzi paradoksalnie skomplikowało proces odkrywania wiedzy, ponieważ cenne informacje są rozproszone na różnych platformach, takich jak wątki e-mailowe i repozytoria dokumentów w organizacjach, co prowadzi do:
- •Powielania wysiłków badawczych
- •Trudności w szybkim uzyskaniu dostępu do odpowiedniej wiedzy specjalistycznej
- •Obciążenie związane z przełączaniem się między kontekstami (specjaliści korzystają średnio z 9 narzędzi dziennie)
- •Ograniczone możliwości wyszukiwania, ograniczone do dopasowywania słów kluczowych
- •Problemy z kontrolą wersji i złożoność dostępu
- •67% cennych informacji nie dociera do odpowiednich odbiorców
Rozwiązanie
Wdrożone rozwiązanie obejmowało architekturę rozproszoną do zarządzania wiedzą opartą na sztucznej inteligencji. Wykorzystywało ono przetwarzanie języka naturalnego wraz z funkcjami i inteligentną kuracją treści.
Architektura systemu System wykorzystuje framework mikrousług skoncentrowany na przetwarzaniu treści i rozumieniu znaczenia na poziomie, z naciskiem na:
- •Pobieranie i przetwarzanie treści ze źródeł przy użyciu standardowych interfejsów API
- •Modele oparte na transformatorach do rozumienia semantycznego
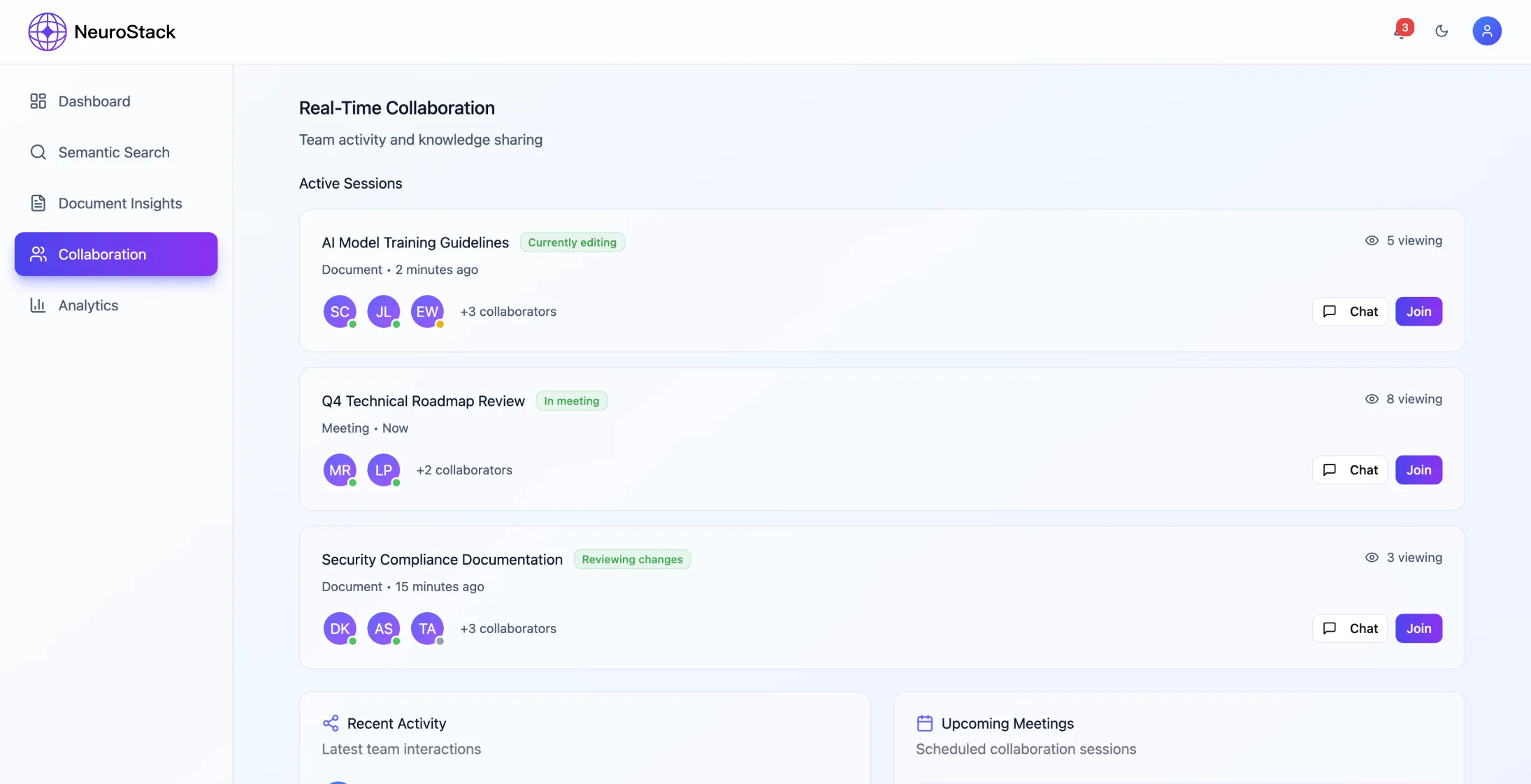
- •Zarządzanie wspólną przestrzenią roboczą
- •Synchronizacja w czasie rzeczywistym i precyzyjne zarządzanie uprawnieniami
Podstawowe komponenty
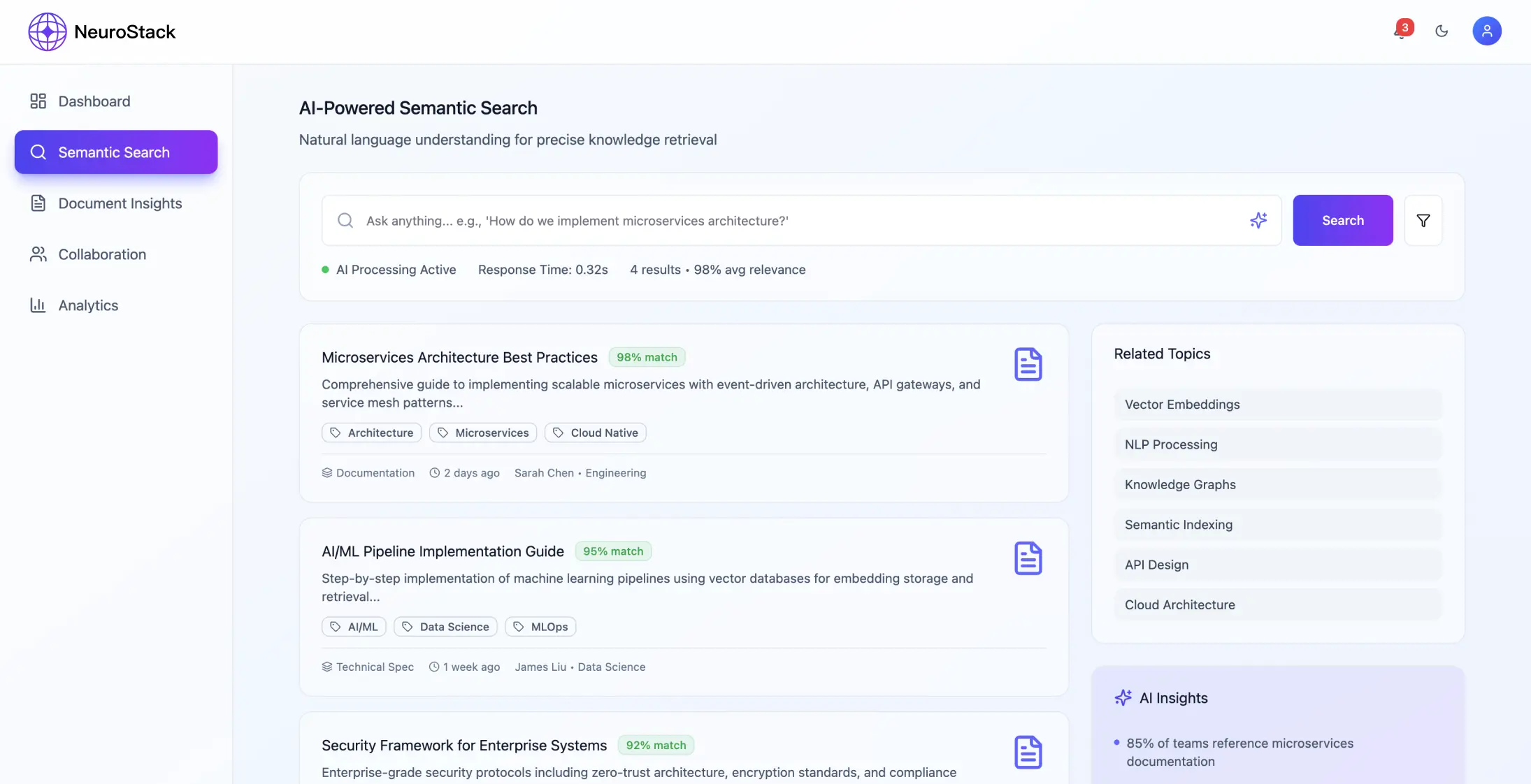
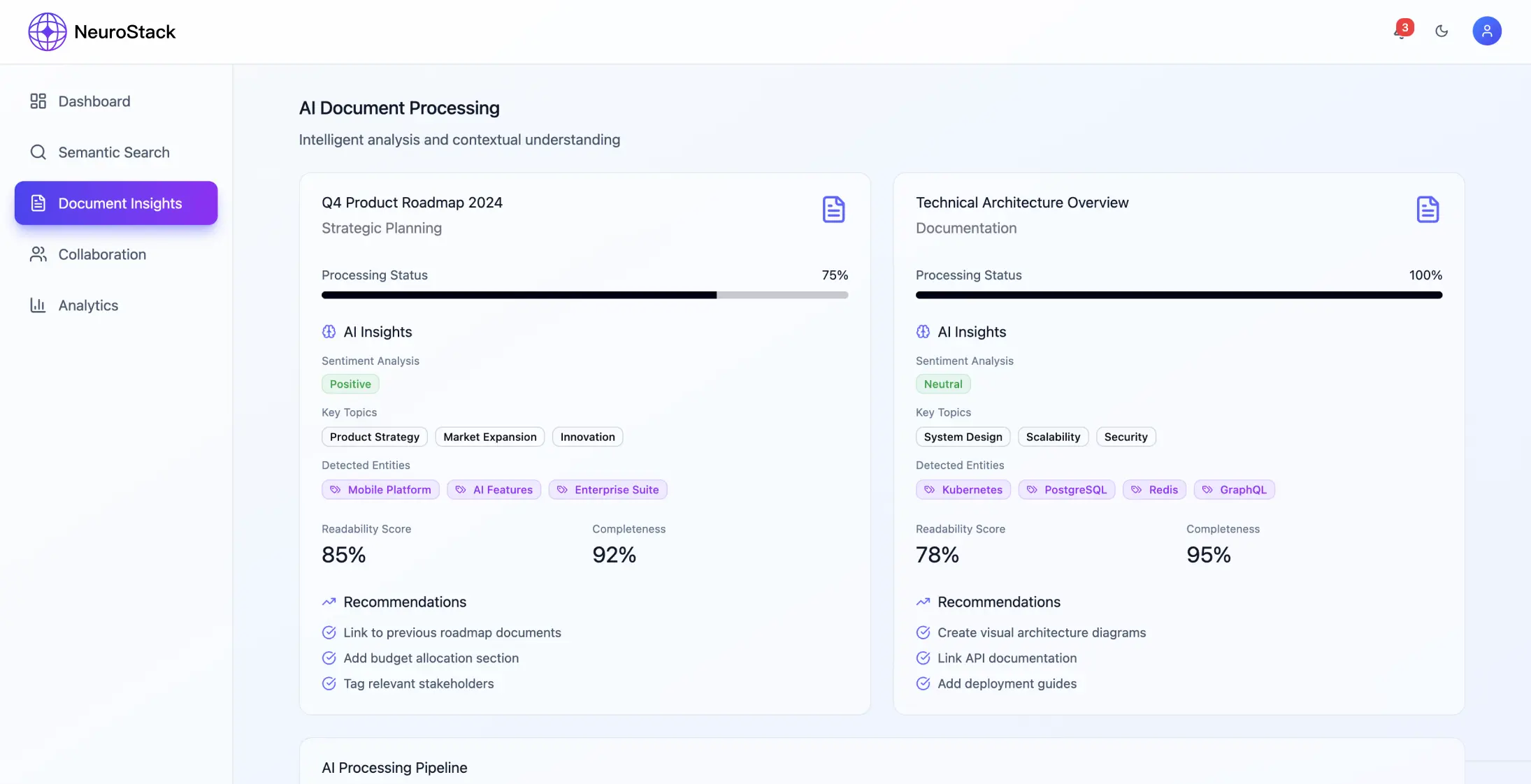
- •Przetwarzanie dokumentów: obsługa plików PDF, stron internetowych, wiadomości e-mail w różnych formatach danych strukturalnych
- •Usługa przetwarzania zapytań: wyszukiwanie w języku naturalnym i ranking kontekstowy
- •Pobieranie treści: interfejsy API z przetwarzaniem NLP w celu ulepszenia semantycznego
- •Przechowywanie: bazy danych wektorowych i graficznych w celu ulepszonego wyszukiwania
- •Bezpieczeństwo: szyfrowanie typu end-to-end z uwierzytelnianiem OAuth 2.0
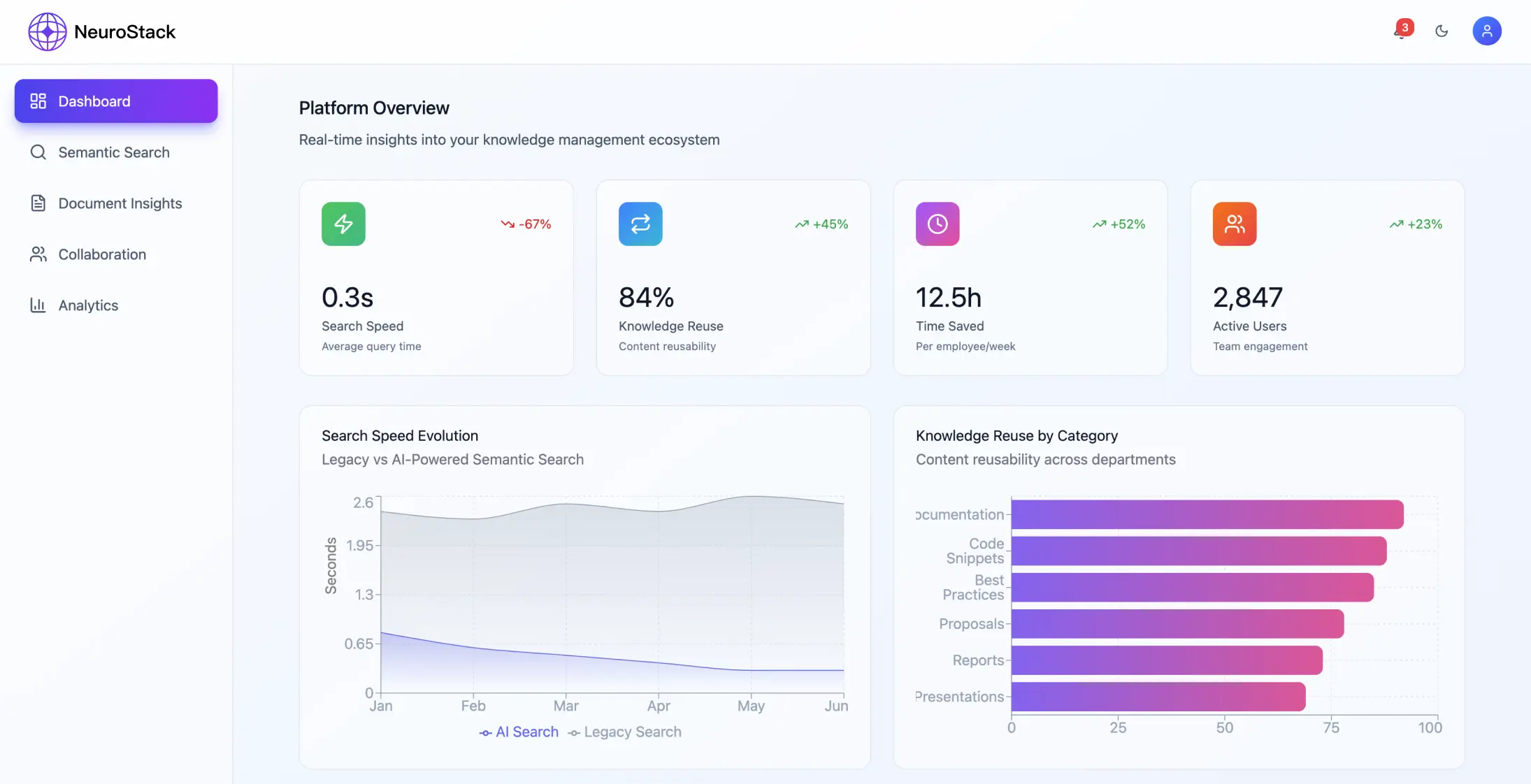
Wyniki wdrożenia
Wskaźniki wydajności Systemowi udało się osiągnąć znaczną poprawę:
- •68% skrócenie czasu wyszukiwania informacji
- •45% wzrost wskaźnika ponownego wykorzystania wiedzy
- •99,94% dokładność trafności wyszukiwania
- •Platforma obsługuje ponad 2 300 000 informacji miesięcznie
- •Odpowiedzi na zapytania w mniej niż 200 milisekund
- •Utrzymanie 99% czasu sprawności
Wpływ na działalność Poprawa wydajności
- •Oszczędność 2–2,5 godziny dziennie, które wcześniej poświęcali Państwo na przeszukiwanie systemów
- •Ponad 40 godzin oszczędności miesięcznie na zespół dzięki ograniczeniu powielania badań
- •45% redukcja czasu szkolenia pracowników dzięki nauce opartej na sztucznej inteligencji Redukcja kosztów
- •34% spadek kosztów związanych z ręcznym przetwarzaniem wiedzy
- •Usprawnione koszty infrastruktury
- •Zmniejszone wymagania dotyczące wsparcia dzięki automatyzacji Zaangażowanie użytkowników
- •214% wzrost wykorzystania przestrzeni roboczej zespołu
- •91% wskaźnik dokładności rekomendacji
- •Ulepszona współpraca w zakresie dzielenia się wiedzą
Sukces platformy wynikał z jej stopniowego rozwoju, regularnego uwzględniania opinii użytkowników oraz optymalizacji wydajności w trakcie całego procesu.
Wdrożenie techniczne
Proces rozwoju Prace rozwojowe przebiegały zgodnie z metodologią obejmującą:
- •zwinne sprinty z dedykowanym potokiem AI/ML
- •infrastrukturę jako kod zapewniającą spójność środowisk
- •automatyczne testowanie, w tym scenariusze jednostkowe, integracyjne i wydajnościowe
- •system flag funkcji umożliwiający kontrolowane wydania
- •Testy A/B w celu ulepszenia algorytmu rekomendacji
Strategia wdrażania
- •Zarządzanie środowiskiem: Tworzenie, testowanie i produkcja z identycznymi ustawieniami
- •Potok CI/CD: zautomatyzowane procesy kompilacji, testowania i wdrażania
- •Koordynacja kontenerów: wykorzystanie Kubernetes/Docker Swarm
- •Monitorowanie: rozproszone śledzenie, wskaźniki wydajności i zautomatyzowana reakcja na incydenty
Gotowi na transformację zarządzania wiedzą?
Odkryj, jak rozwiązania oparte na sztucznej inteligencji mogą zrewolucjonizować przepływ informacji w Państwa organizacji.
Wnioski
Kluczowe spostrzeżenia Wzorce adopcji przez użytkowników
- •Prostsze funkcje osiągają wyższe wskaźniki adopcji
- •Stopniowe wprowadzanie funkcji działa lepiej niż kompleksowe szkolenia
- •Narzędzia muszą płynnie integrować się z istniejącymi procesami pracy Kwestie techniczne
- •Wydajność wyszukiwania podobieństw wektorowych spada wraz z rozmiarem bazy danych
- •Ocena jakości treści ma kluczowe znaczenie od momentu wdrożenia
- •Współpraca w zakresie edycji w czasie rzeczywistym wymaga starannego rozwiązywania konfliktów
Pokonane wyzwania Problemy ze skalowalnością
- •Optymalizacja wydajności bazy danych poprzez buforowanie zapytań
- •Przejście z architektury synchronicznej na architekturę opartą na zdarzeniach
- •Wdrożenie ograniczeń szybkości i wyłączników awaryjnych Zarządzanie jakością treści
- •Automatyczna ocena treści na podstawie wiarygodności źródła
- •Mechanizmy informacji zwrotnej od użytkowników dotyczące dokładności wyszukiwania
- •Równowaga między ilością treści a jakością selekcji
Ograniczanie ryzyka
Platforma obejmuje kompleksowe strategie ograniczania ryzyka:
- •Procesy tworzenia kopii zapasowych i odzyskiwania danych w określonym momencie
- •Plany odzyskiwania danych po awarii usług AI
- •Zarządzanie zależnościami zewnętrznych interfejsów API
- •Zautomatyzowane systemy reagowania na incydenty
- •Dokładne monitorowanie z możliwością przywrócenia stanu poprzedniego na podstawie wydajności
Aby utrzymać zaufanie użytkowników i skuteczność systemu, należy skupić się przede wszystkim na jakości treści, a nie na ich ilości.
Kwestie do rozważenia w przyszłości
Obszary optymalizacji Poprawa wydajności
- •Udoskonalenie strategii buforowania dla potrzeb treści w czasie rzeczywistym
- •Optymalizacja indeksów dla rosnących zbiorów danych
- •Równoważenie obciążenia dla scenariuszy równoczesnego korzystania przez wielu użytkowników Architektura integracji
- •Przejście z architektury punkt-punkt na architekturę opartą na webhookach
- •Standaryzacja formatów danych użytkowych w celu integracji narzędzi
- •Zwiększona niezawodność dzięki projektowi systemu rozproszonego Sukces tej platformy zarządzania wiedzą opartej na sztucznej inteligencji pokazuje ogromny potencjał poprawy wydajności organizacji dzięki inteligentnemu przetwarzaniu informacji i płynnemu projektowaniu doświadczeń użytkownika.
Wyniki projektu
- 68% skrócenie czasu wyszukiwania informacji
- 45% wzrost wskaźnika ponownego wykorzystania wiedzy
- 99.94% dokładności trafności wyszukiwania
- ponad 2 300 000 informacji przetwarzanych miesięcznie
- utrzymanie dostępności na poziomie 99%
Kluczowe wskaźniki wydajności
68%
Skrócenie czasu wyszukiwania
Oszczędność czasu potrzebnego na wyszukiwanie informacji
99.94%
Dokładność wyszukiwania
Dokładność trafności wyszukiwania
45%
Ponowne wykorzystanie wiedzy
Wzrost wskaźników ponownego wykorzystania wiedzy
99%
Czas działania systemu
Dostępność platformy
Wykorzystane technologie
Przetwarzanie języka naturalnego
Mikrousługi
Bazy danych wektorowych
Modele transformatorów
Kubernetes
OAuth 2.0


