Os profissionais do conhecimento muitas vezes lidam com informações espalhadas por várias ferramentas e plataformas. Isso leva a uma diminuição da produtividade e a esforços de trabalho redundantes. Desenvolvemos uma plataforma de gestão do conhecimento alimentada por IA que revoluciona a forma como as organizações lidam e recuperam informações através do processamento de linguagem natural e da curadoria inteligente de conteúdos.
1 of 5
Visão geral do projeto
O Problema
Os profissionais do conhecimento muitas vezes lidam com informações espalhadas por várias ferramentas e plataformas. Isso leva a uma diminuição da produtividade e a esforços de trabalho redundantes.
O panorama moderno do trabalho intelectual é afetado pela natureza dispersa da informação entre sistemas, o que aumenta a pressão e diminui a eficácia geral das organizações. Os métodos convencionais de gestão do conhecimento dependem frequentemente de estruturas e processos de classificação manual que têm dificuldade em acompanhar a evolução das formas como a informação é consumida atualmente.
Desafios atuais
O uso generalizado de ferramentas complicou, ironicamente, o processo de descoberta de conhecimento, uma vez que informações valiosas estão espalhadas por plataformas como threads de e-mail e repositórios de documentos dentro das organizações, levando a:
- •Esforços de pesquisa duplicados
- •Dificuldades em aceder rapidamente a conhecimentos especializados relevantes
- •Sobrecarga de mudança de contexto (os profissionais usam em média 9 ferramentas por dia)
- •Capacidades de pesquisa limitadas restritas à correspondência de palavras-chave
- •Problemas de controlo de versão e complexidade de acesso
- •67% das informações valiosas não chegam ao público certo
A solução
A solução implementada incorporou uma arquitetura distribuída para gestão do conhecimento alimentada por IA. Utilizou processamento de linguagem natural, juntamente com funções e curadoria inteligente de conteúdo.
Arquitetura do sistema
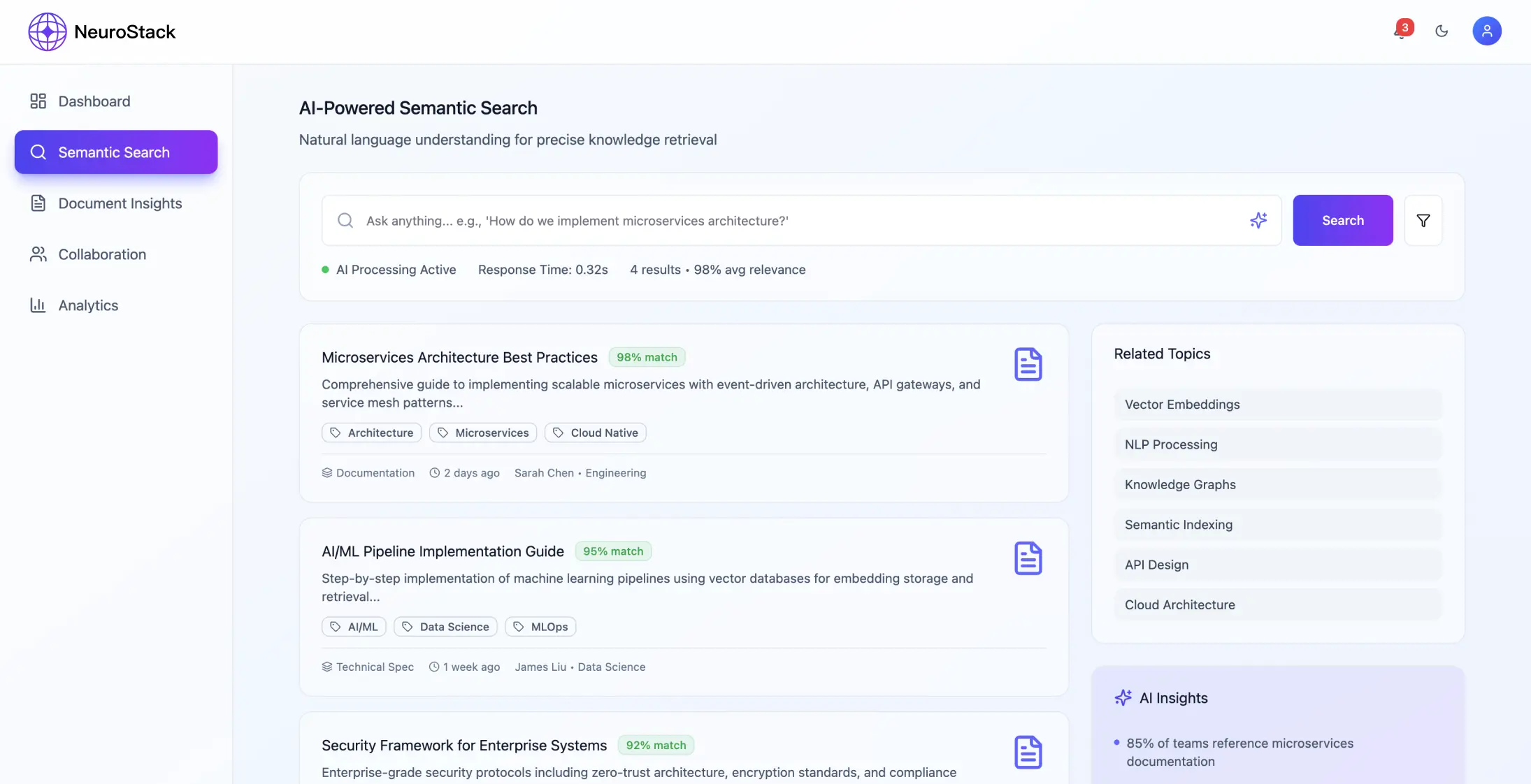
O sistema usa uma estrutura de microsserviços focada no processamento de conteúdo e na compreensão do significado em um nível, com ênfase principal em:
- •Entrada e processamento de conteúdo de fontes usando APIs padrão
- •Modelos baseados em transformadores para compreensão semântica
- •Gestão colaborativa do espaço de trabalho
- •Sincronização em tempo real e gestão precisa de permissões
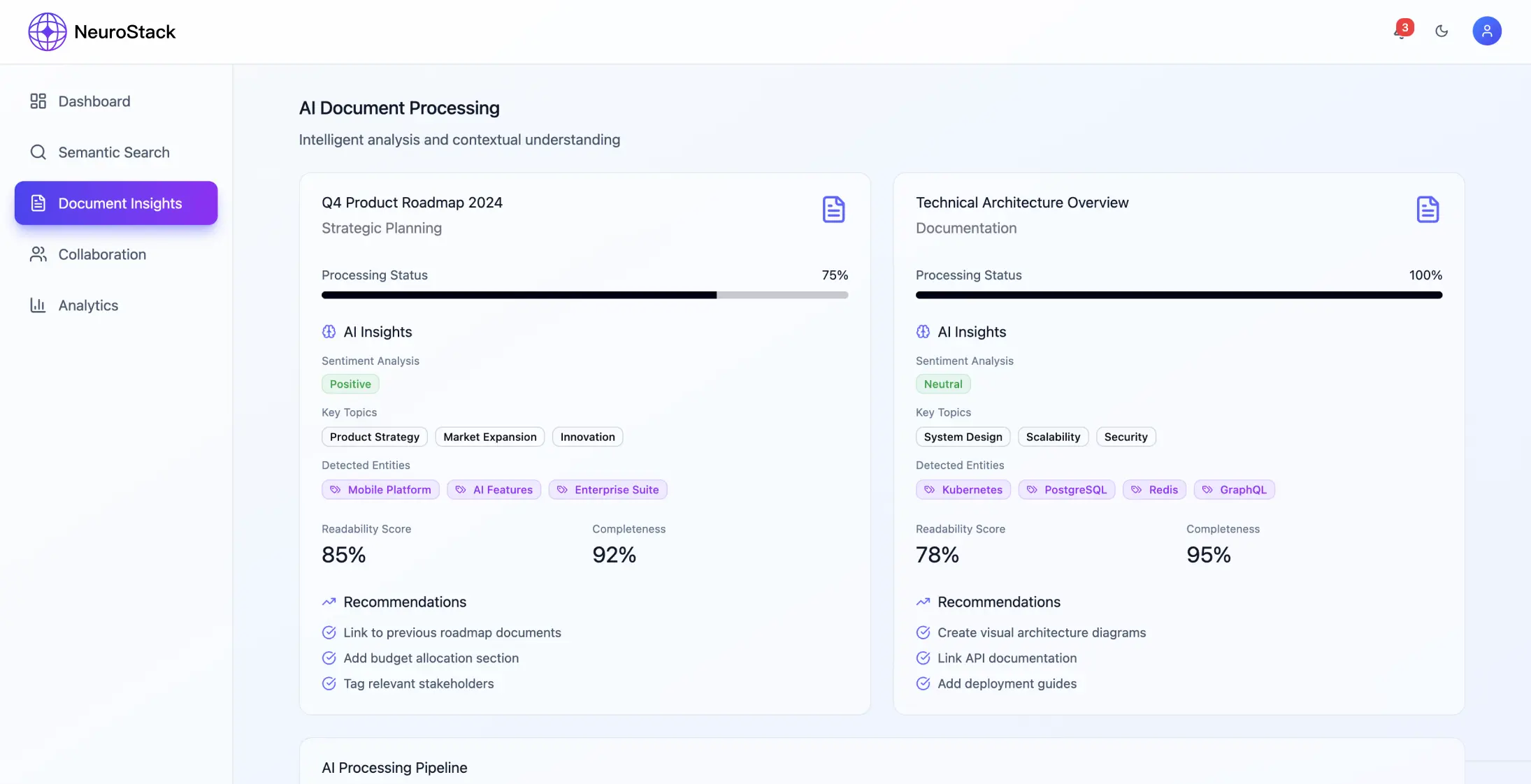
Componentes principais
- •Processamento de documentos: Manuseio de PDFs, páginas da web, e-mails em vários formatos de dados estruturados
- •Serviço de processamento de consultas: pesquisa em linguagem natural e classificação contextual
- •Ingestão de conteúdo: APIs com processamento NLP para aprimoramento semântico
- •Armazenamento: bases de dados vetoriais e gráficas para uma recuperação melhorada
- •Segurança: Criptografia de ponta a ponta com autenticação OAuth 2.0
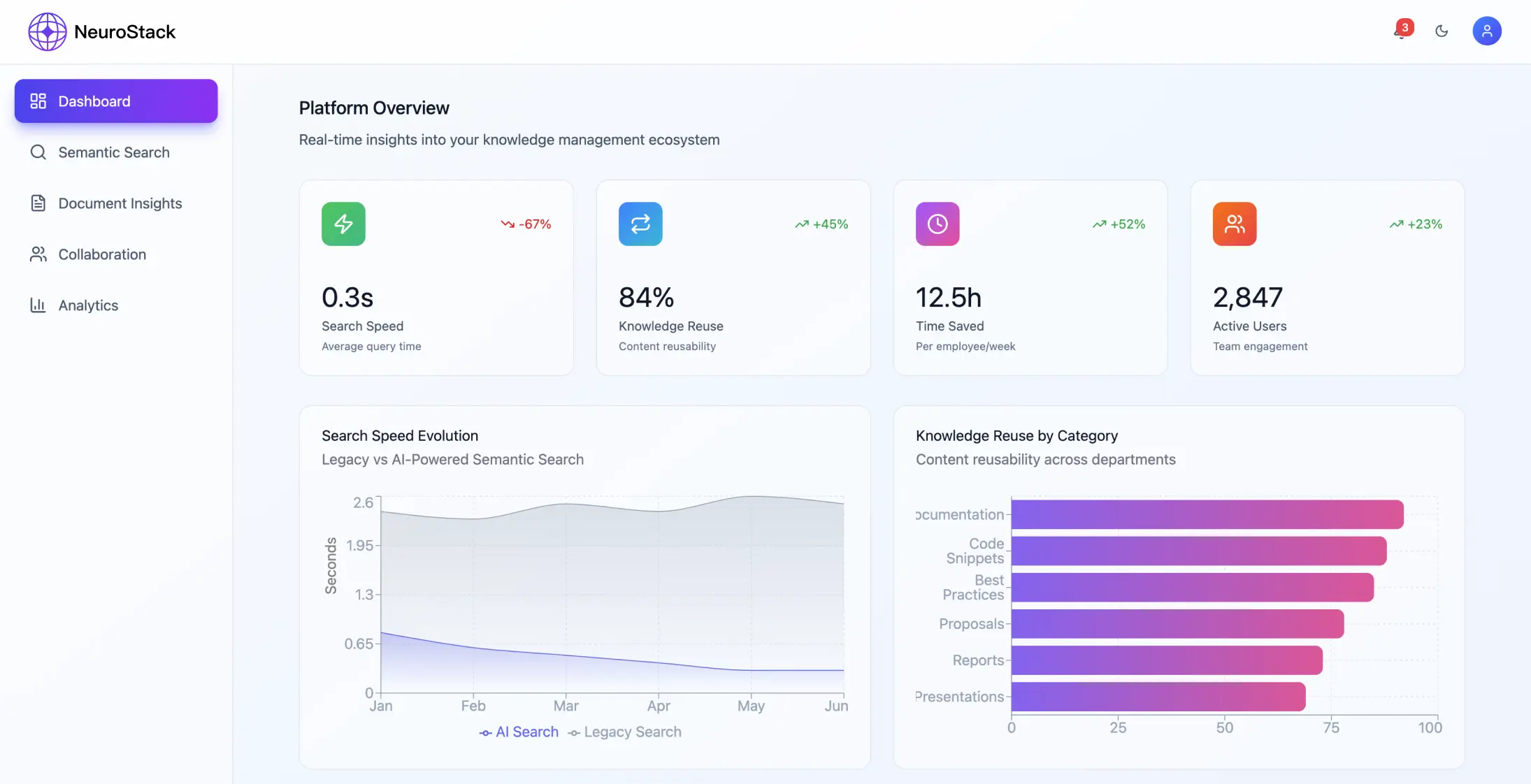
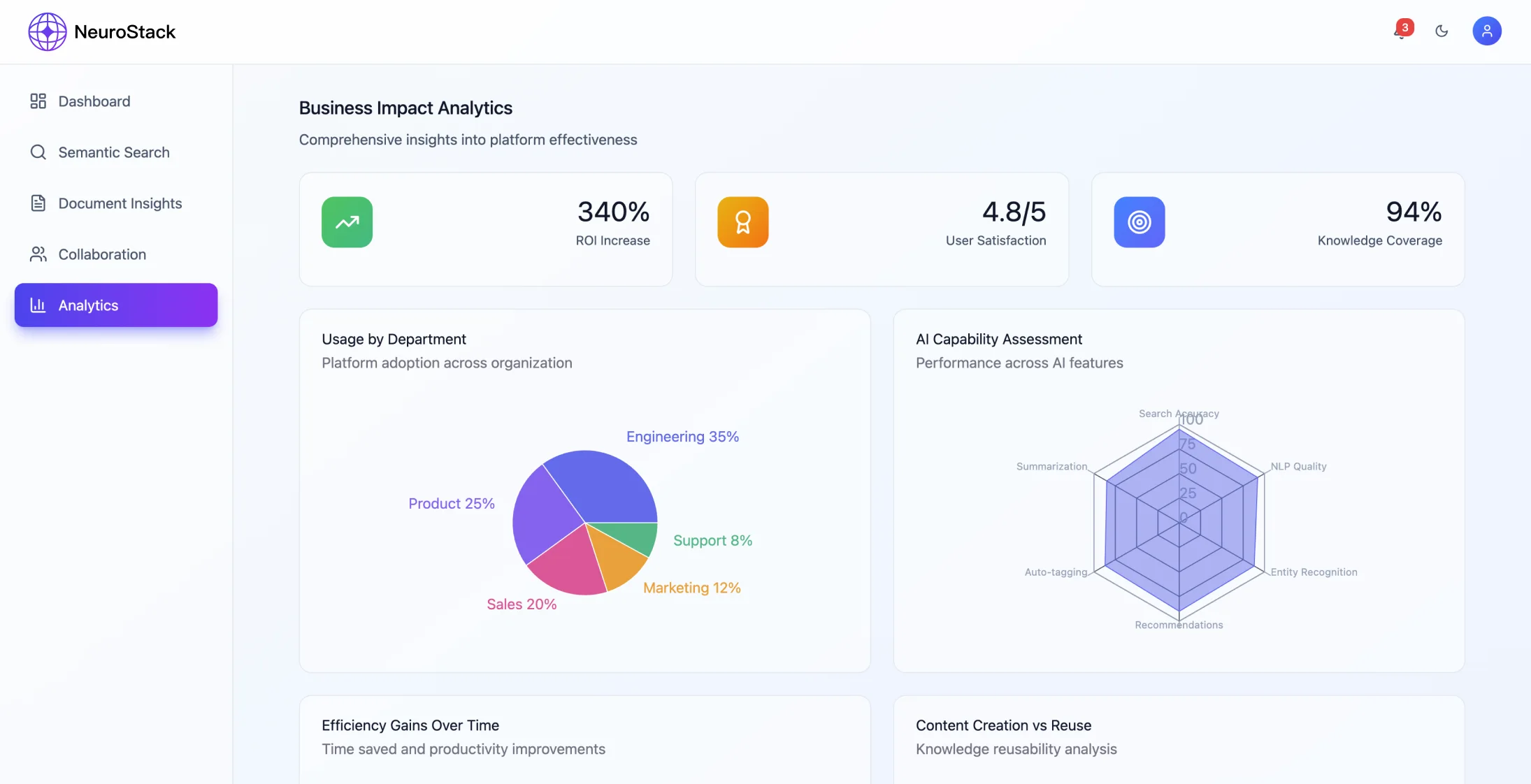
Resultados da implementação
Métricas de desempenho
O sistema conseguiu alcançar melhorias significativas:
- •Redução de 68% no tempo de recuperação de informações
- •Aumento de 45% nas taxas de reutilização de conhecimento
- •99,94% de precisão na relevância da pesquisa
- •A plataforma lida com mais de 2.300.000 informações por mês
- •Respostas a consultas em menos de 200 milissegundos
- •99% de tempo de atividade mantido
Impacto nos negócios
Melhorias de eficiência
- •Economizou 2 a 2,5 horas por dia que antes eram gastas pesquisando em vários sistemas
- •Mais de 40 horas economizadas por equipa mensalmente através da redução da duplicação de pesquisas
- •Redução de 45% no tempo de formação dos funcionários através da aprendizagem orientada por IA
Redução de custos
- •Redução de 34% na sobrecarga de manuseio manual de conhecimento
- •Custos de infraestrutura simplificados
- •Menos necessidade de suporte por causa da automação
Envolvimento do utilizador
- •Aumento de 214% na utilização do espaço de trabalho da equipa
- •91% de precisão nas recomendações
- •Partilha de conhecimento colaborativa melhorada
O sucesso da plataforma foi impulsionado pelo desenvolvimento incremental, com integração regular do feedback dos utilizadores e otimização do desempenho ao longo do processo.
Implementação técnica
Processo de desenvolvimento
O desenvolvimento seguiu a metodologia com:
- •Sprints ágeis com pipeline dedicado de IA/ML
- •Infraestrutura como código para ambientes consistentes
- •Testes automatizados, incluindo cenários de unidade, integração e desempenho
- •Sistema de sinalizadores de funcionalidades para lançamentos controlados
- •Testes A/B para melhorar o algoritmo de recomendação
Estratégia de implementação
- •Gestão do ambiente: Desenvolvimento, preparação e produção com configurações idênticas
- •Pipeline de CI/CD: processos automatizados de compilação, teste e implementação
- •Orquestração de contentores: Usando Kubernetes/Docker Swarm
- •Monitorização: rastreamento distribuído, métricas de desempenho e resposta automatizada a incidentes
Pronto para transformar a sua gestão do conhecimento?
Descubra como as soluções baseadas em IA podem revolucionar o fluxo de trabalho de informações da sua organização.
Lições aprendidas
Principais insights
Padrões de adoção do utilizador
- •Recursos mais simples alcançam taxas de adoção mais altas
- •A introdução gradual de funcionalidades funciona melhor do que uma formação abrangente
- •As ferramentas devem integrar-se facilmente nos fluxos de trabalho existentes
Considerações técnicas
- •A eficiência da pesquisa de similaridade vetorial diminui com o tamanho do banco de dados
- •A avaliação da qualidade do conteúdo é crucial desde o início da implementação
- •A edição colaborativa em tempo real requer uma resolução cuidadosa de conflitos
Desafios superados
Problemas de escalabilidade
- •Otimização do desempenho do banco de dados por meio do cache de consultas
- •Transição de arquitetura síncrona para arquitetura orientada a eventos
- •Implementação de limitação de taxa e disjuntores
Gestão da qualidade do conteúdo
- •Pontuação automatizada do conteúdo com base na confiabilidade da fonte
- •Mecanismos de feedback do utilizador para precisão da pesquisa
- •Equilibre o volume de conteúdo e a qualidade da curadoria
Mitigação de riscos
A plataforma inclui estratégias abrangentes de redução de riscos:
- •Processos de backup e recuperação de dados em tempo real
- •Planos de recuperação de desastres para falhas no serviço de IA
- •Gestão de dependências de API externa
- •Sistemas automatizados de resposta a incidentes
- •Monitoramento completo com recursos de reversão baseados no desempenho
É essencial focar inicialmente na qualidade do conteúdo em vez da quantidade para manter a confiança do utilizador e a eficácia do sistema.
Considerações futuras
Áreas de otimização
Melhoria de desempenho
- •Aperfeiçoamento da estratégia de cache para necessidades de conteúdo em tempo real
- •Otimização do índice para conjuntos de dados em crescimento
- •Balanceamento de carga para cenários de usuários simultâneos
Arquitetura de integração
- •Transição de uma arquitetura de eventos ponto a ponto para uma arquitetura baseada em webhooks
- •Formatos de carga útil padronizados para integração de ferramentas
- •Maior confiabilidade através do design de sistema distribuído
O sucesso desta plataforma de gestão do conhecimento alimentada por IA demonstra o potencial significativo para melhorar a produtividade organizacional através do tratamento inteligente da informação e do design de uma experiência de utilizador perfeita.
Resultados do projeto
- Redução de 68% no tempo de recuperação de informações
- Aumento de 45% nas taxas de reutilização de conhecimento
- 99,94% de precisão na relevância da pesquisa
- Mais de 2.300.000 informações processadas mensalmente
- 99% de tempo de atividade mantido
Principais métricas de desempenho
68%
Redução do tempo de recuperação
Tempo poupado na recuperação de informações
99,94%
Precisão da pesquisa
Precisão da relevância da pesquisa
45%
Reutilização do conhecimento
Aumento nas taxas de reutilização de conhecimento
99%
Tempo de atividade do sistema
Disponibilidade da plataforma
Tecnologias utilizadas
Processamento de linguagem natural
Microsserviços
Bases de dados vetoriais
Modelos de transformadores
Kubernetes
OAuth 2.0


