Працівники, що працюють з інформацією, часто мають справу з інформацією, розкиданою по різних інструментах і платформах. Це призводить до зниження продуктивності та надмірних зусиль. Ми розробили платформу управління знаннями на базі штучного інтелекту, яка революціонізує спосіб обробки та пошуку інформації в організаціях за допомогою обробки природної мови та інтелектуального кураторства контенту.
1 of 5
Огляд проекту
Проблема
Інтелектуальні працівники часто мають справу з інформацією, розкиданою між різними інструментами та платформами. Це призводить до зниження продуктивності та надмірних зусиль.
Сучасний ландшафт інтелектуальної праці страждає від розрізненості інформації між системами, що додає навантаження і знижує загальну ефективність організацій. Традиційні методи управління знаннями часто залежать від структур і ручних процесів сортування, які не встигають за сучасними способами споживання інформації.
Поточні виклики
Широке використання інструментів, як не дивно, ускладнило процес пошуку знань, оскільки цінна інформація розкидана по різних платформах, таких як ланцюжки електронних листів та репозиторії документів всередині організацій, що призводить до:
- •Дублювання досліджень
- •Труднощі в оперативному доступі до відповідних експертних знань
- •Накладні витрати на перемикання контексту (фахівці в середньому використовують 9 інструментів щодня)
- •Обмежені можливості пошуку, що обмежуються відповідністю ключових слів
- •Проблеми з контролем версій та складність доступу
- •67% цінної інформації не досягає відповідної аудиторії
Рішення
Впроваджене рішення включало розподілену архітектуру для управління знаннями на базі штучного інтелекту. Воно використовувало обробку природної мови, а також функції та інтелектуальну курацію контенту.
Архітектура системи
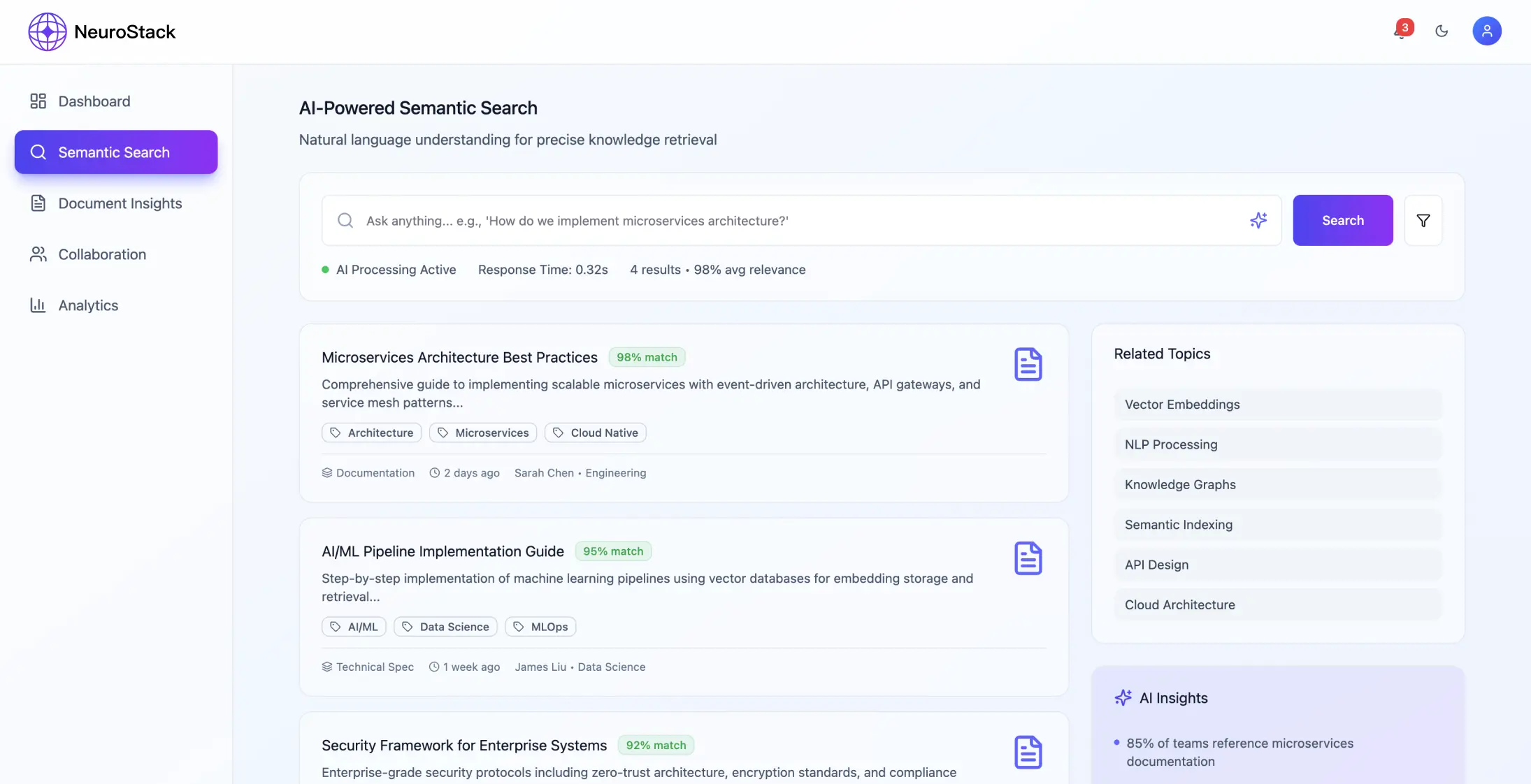
Система використовує фреймворк мікросервісів, орієнтований на обробку контенту та розуміння значення на певному рівні, з основним акцентом на:
- •Прийом та обробка контенту з джерел за допомогою стандартних API
- •Моделі на основі трансформерів для семантичного розуміння
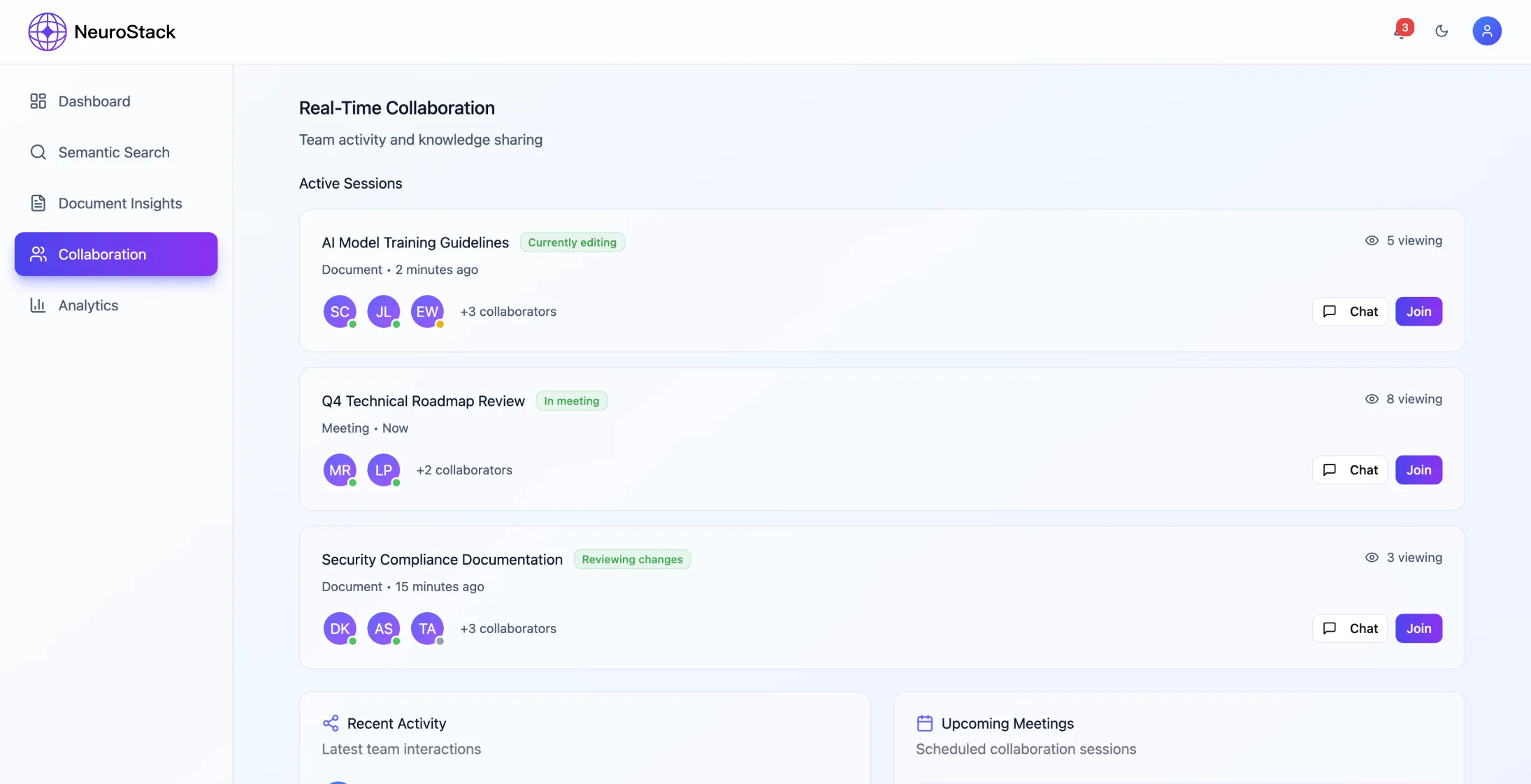
- •Спільне управління робочим простором
- •Синхронізація в режимі реального часу та точне управління дозволами
Основні компоненти
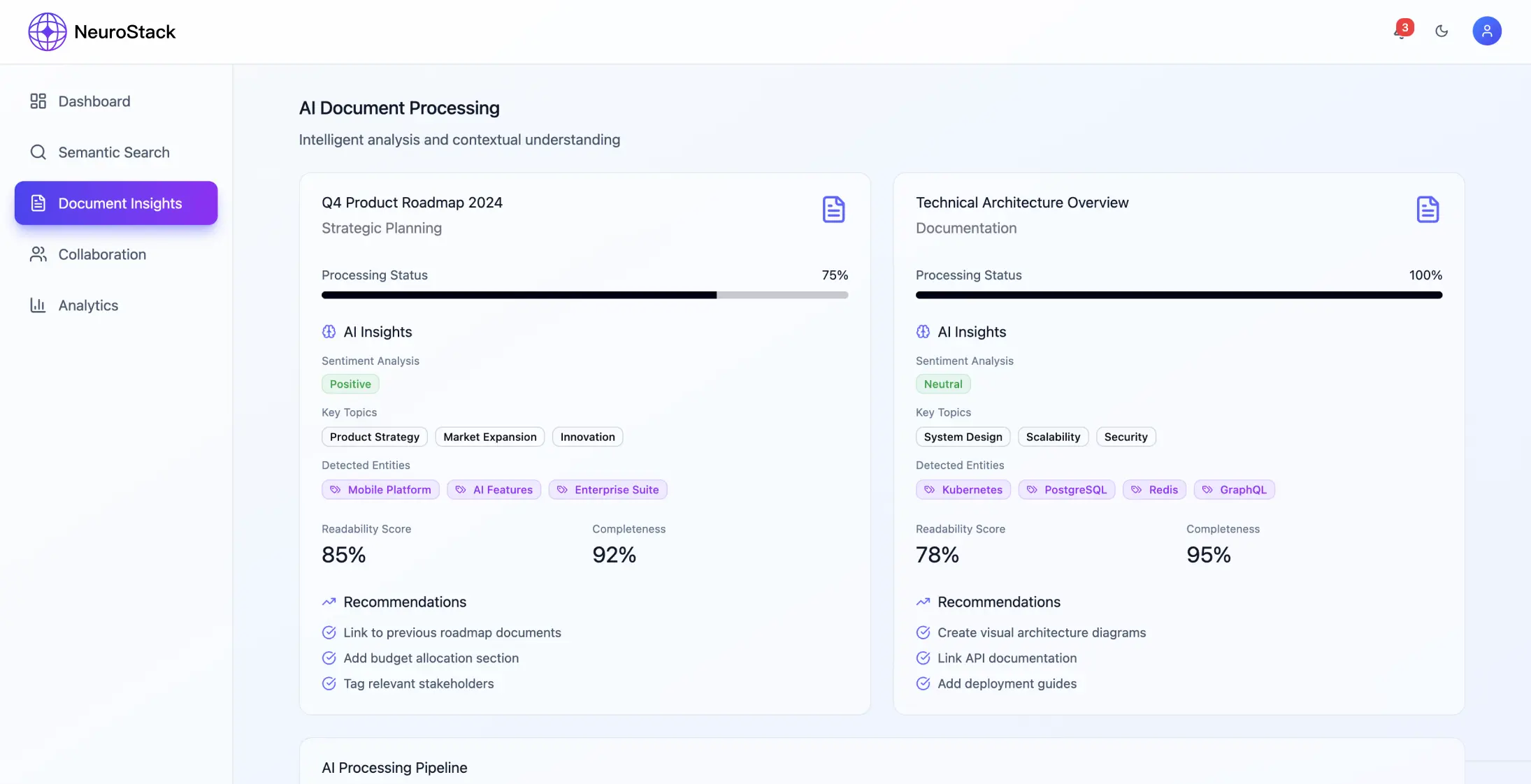
- •Обробка документів: обробка PDF-файлів, веб-сторінок, електронних листів у різних структурованих форматах даних
- •Служба обробки запитів: пошук за природною мовою та контекстне ранжування
- •Введення вмісту: API з обробкою NLP для семантичного вдосконалення
- •Зберігання: векторні та графічні бази даних для покращеного пошуку
- •Безпека: наскрізне шифрування з аутентифікацією OAuth 2.0
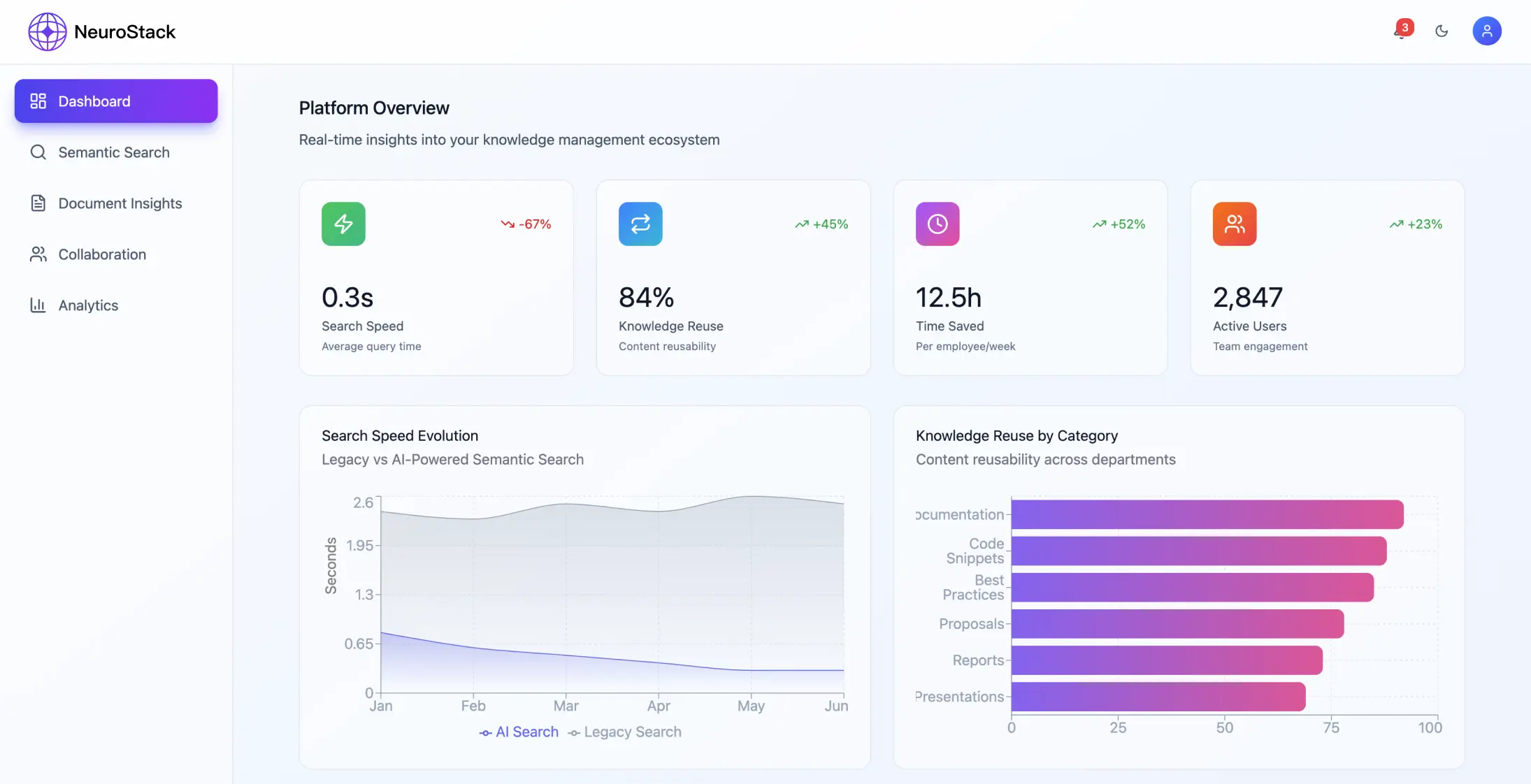
Результати впровадження
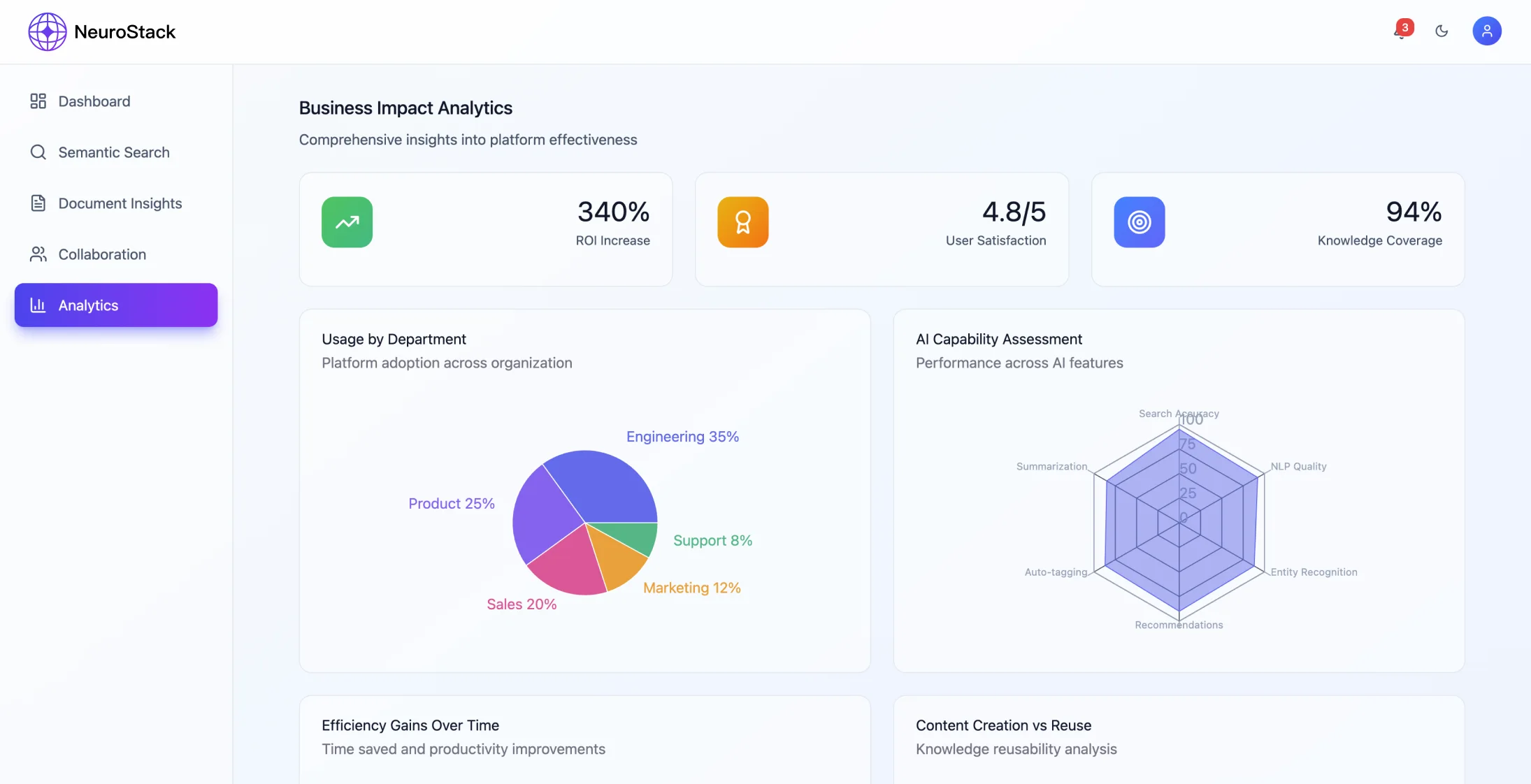
Показники ефективності
Система змогла досягти значних поліпшень:
- •68% скорочення часу на пошук інформації
- •45% зростання рівня повторного використання знань
- •99,94% точність релевантності пошуку
- •Платформа обробляє понад 2 300 000 одиниць інформації щомісяця
- •Відповіді на запити за менш ніж 200 мілісекунд
- •99% часу безперебійної роботи
Вплив на бізнес
Покращення ефективності
- •Економія 2-2,5 годин на день, які раніше витрачалися на пошук у різних системах
- •Економія понад 40 годин на місяць для кожної команди завдяки зменшенню дублювання досліджень
- •45% скорочення часу на навчання співробітників завдяки навчанню з використанням штучного інтелекту
Зниження витрат
- •34% зменшення витрат на ручну обробку знань
- •Оптимізовані витрати на інфраструктуру
- •Зменшення вимог до технічної підтримки завдяки автоматизації
Взаємодія з користувачами
- •214% збільшення використання робочого простору команди
- •91% точність рекомендацій
- •Розширений спільний обмін знаннями
Успіх платформи був обумовлений поступовим розвитком з регулярним врахуванням відгуків користувачів та оптимізацією продуктивності протягом усього процесу.
Технічна реалізація
Процес розробки
Розробка здійснювалася відповідно до методології з:
- •Гнучкі спринти з виділеним конвеєром AI/ML
- •Інфраструктура як код для узгоджених середовищ
- •Автоматизоване тестування, включаючи сценарії модульного, інтеграційного та продуктивного тестування
- •Система прапорців функцій для контрольованих випусків
- •A/B-тестування для вдосконалення алгоритму рекомендацій
Стратегія розгортання
- •Управління середовищем: розробка, тестування та виробництво з ідентичними налаштуваннями
- •CI/CD Pipeline: автоматизовані процеси побудови, тестування та розгортання
- •Оркестрування контейнерів: використання Kubernetes/Docker Swarm
- •Моніторинг: розподілене відстеження, показники продуктивності та автоматизована реакція на інциденти
Готові трансформувати управління знаннями?
Дізнайтеся, як рішення на основі штучного інтелекту можуть революціонізувати інформаційний робочий процес вашої організації.
Висновки
Ключові висновки
Моделі прийняття користувачами
- •Простіші функції досягають вищих показників прийняття
- •Поступове впровадження функцій працює краще, ніж комплексне навчання
- •Інструменти повинні легко інтегруватися в існуючі робочі процеси
Технічні міркування
- •Ефективність векторного пошуку за схожістю зменшується із збільшенням розміру бази даних
- •Оцінка якості контенту має вирішальне значення з самого початку впровадження
- •Спільне редагування в режимі реального часу вимагає ретельного вирішення конфліктів
Подолані виклики
Проблеми з масштабованістю
- •Оптимізація продуктивності бази даних за допомогою кешування запитів
- •Перехід від синхронної до подійно-орієнтованої архітектури
- •Впровадження обмеження швидкості та автоматичних вимикачів
Управління якістю контенту
- •Автоматична оцінка вмісту на основі надійності джерела
- •Механізми зворотного зв'язку з користувачами для підвищення точності пошуку
- •Збалансуйте обсяг контенту та якість курації
Зниження ризиків
Платформа включає комплексні стратегії зниження ризиків:
- •Процеси резервного копіювання та відновлення даних на певний момент часу
- •Плани відновлення після аварій у разі збою роботи служб штучного інтелекту
- •Управління зовнішніми API-залежностями
- •Автоматизовані системи реагування на інциденти
- •Ретельний моніторинг з можливістю відкоту на основі продуктивності
Початковий акцент на якості контенту, а не на його кількості, є важливим для збереження довіри користувачів та ефективності системи.
Майбутні міркування
Області оптимізації
Покращення продуктивності
- •Удосконалення стратегії кешування для потреб контенту в режимі реального часу
- •Оптимізація індексу для зростаючих наборів даних
- •Балансування навантаження для сценаріїв одночасного використання користувачами
Архітектура інтеграції
- •Перехід від архітектури подій «точка-точка» до архітектури на основі веб-хуків
- •Стандартизовані формати корисного навантаження для інтеграції інструментів
- •Підвищена надійність завдяки дистрибутивній системі проектування
Успіх цієї платформи управління знаннями на базі штучного інтелекту демонструє значний потенціал для підвищення продуктивності організації за допомогою інтелектуальної обробки інформації та безперебійного дизайну користувацького досвіду.
Результати проекту
- Скорочення часу пошуку інформації на 68%
- 45% збільшення рівня повторного використання знань
- 99,94% точність релевантності пошуку
- Щомісяця обробляється понад 2 300 000 одиниць інформації
- 99% часу безперебійної роботи
Ключові показники ефективності
68%
Скорочення часу пошуку
Економія часу на пошук інформації
99,94%
Точність пошуку
Точність релевантності пошуку
45%
Повторне використання знань
Збільшення рівня повторного використання знань
99%
Час безвідмовної роботи системи
Доступність платформи
Використані технології
Обробка природної мови
Мікросервіси
Векторні бази даних
Моделі трансформаторів
Kubernetes
OAuth 2.0


